И снова про ИИ
Oct. 9th, 2024 07:28 pmВ очередной раз убедился что ИИ это какая то игрушка, дал им каждому по очереди решать простую геометрическую задачку, какой я ерунды только не начитался.
--
Для улучшения качества языковых моделей (LLM) придумали RLHF, обучение на основе обратной связи от человека. В результате применения этого подхода LLM научились лучше убеждать людей в правильности ответа. При этом качество самих ответов ухудшилось, но ошибки стали более труднообнаруживаемыми.
https://arxiv.org/abs/2409.12822
--
Собственно сама задачка
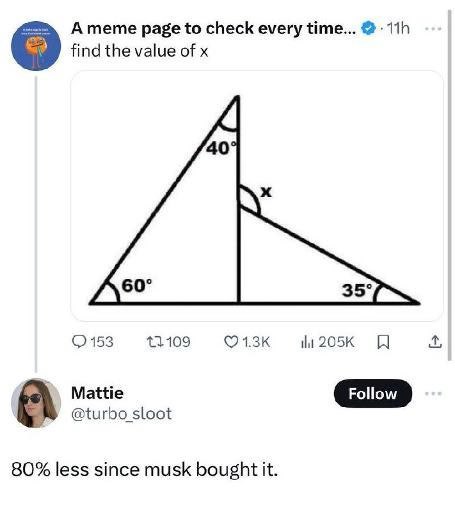
--
Для улучшения качества языковых моделей (LLM) придумали RLHF, обучение на основе обратной связи от человека. В результате применения этого подхода LLM научились лучше убеждать людей в правильности ответа. При этом качество самих ответов ухудшилось, но ошибки стали более труднообнаруживаемыми.
https://arxiv.org/abs/2409.12822
--
Собственно сама задачка